5.1 Using Compressions
This section outlines the currently available methods for compressing
the state machine representing a process, and gives some guidance in how
and when to use them.
5.1.1 Methods of compression
FDR currently provides six different methods of taking a transition
system (or state machine) and attempting to compress it into a more
efficient one.
Each compression function must first be declared by the transparent
operator before it can be used (see section Transparent).
The functions must be spelt exactly as given below or the relevant
operation will not take place — in fact, since they are transparent,
FDR will ignore an unknown function (i.e., treat it as the identity
function) and simply give a warning in the status window
(see section Options).
-
explicate
Enumeration: by simply tabulating the transition system, rather than
deducing the operational semantics “on the fly”.
This obviously cannot reduce the number of nodes, but does allow them to
be represented by small (integer) values, as opposed to a representation
of their natural structure.
This in turn makes subsequent manipulations substantially faster.
-
sbisim
Strong, node-labelled, bisimulation: the standard notion enriched (as
discussed in [Roscoe94]) by the minimal acceptance and divergence
labelling of the nodes.
This was used in FDR1 for the final stage of normalising
specifications.
-
wbisim
Divergence respecting weak bisimulation.
-
tau_loop_factor
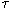 -loop
-loopelimination: since a process may choose automatically to follow a
action, it follows that all the processes on a
-loop(or, more properly, in a strongly connected component under
-reachability)are equivalent.
-
diamond
Diamond elimination: this carries out the node-compression discussed in
the last section systematically, so as to include as few nodes as
possible in the output graph.
This is perhaps the most novel of the techniques, and the technical
details are discussed in Diamond elimination.
-
normalise
Normalisation: discussed extensively elsewhere,(11)
this can give significant gains, but it suffers from the disadvantage
that by going through powerspace nodes it can be expensive and lead to
expansion.
Normalisation (as described in Checking refinement) is essential
(and automatically applied, if needed) for the top level of the
left-hand side of a refinement check, but in FDR is made available
as a general compression technique through the transparent function
normalise.
(For historical reasons, this function is also available as
normal and normalize.)
-
model_compress
Factoring by semantic equivalence: the compositional models of CSP we
are using all represent much weaker congruences than bisimulation.
Therefore, if we can afford to compute the semantic equivalence relation
over states it will give better compression than bisimulation to factor
by this equivalence relation.
It makes sense to factorise only by the model in which the check is
being carried out.
This is therefore made an implicit parameter to a single transparent
function model_compress.
The technical details of this method are discussed in Computing semantic equivalence.
Both
-loopelimination and factoring by a semantic equivalence use the notion of
factoring a GLTS by an equivalence relation; details can be found in
[RosEtAl95].
5.1.2 Compressions in context
FDR will take a complex CSP description and build it up in stages,
compressing the resulting process each time.
Ultimately we expect these decisions to be at least partly automated,
but in current versions almost all compression directives must be
included in the syntax of the process in question.
At present, the only automatic applications of these techniques are:
-
Bisimulation of all “low-level” leaf processes (by construction).
-
Normalisation of the left hand side of a check.
One of the most interesting and challenging things when incorporating
these ideas is preserving the debugging functionality of the system.
The debugging process becomes hierarchical: at the top level we will
find erroneous behaviours of compressed parts of the system; we will
then have to debug the pre-compressed forms for the appropriate
behaviour, and so on down.
On very large systems (such as that discussed in the next section) it
will not be practical to complete this process for all parts of the
system.
Therefore the debugging facility initially works out subsystem
behaviours down no further than the highest level compressed processes,
and only investigates more deeply when directed by the user (as
described in The FDR Process Debugger and Debugging).
The way a system is composed together can have an enormous influence on
the effectiveness of hierarchical compression.
The following principles should generally be followed:
-
Put processes which communicate with each other together early.
For example, in the dining philosophers, you should build up the system
out of consecutive fork/philosopher pairs rather than putting the
philosophers all together, the forks all together and then putting these
two processes together at the highest level.
-
Hide all events at as low a level as is possible.
The laws of CSP allow the movement of hiding inside and outside a
parallel operator as long as its synchronisations are not interfered
with.
In general therefore, any event that is to be hidden should be hidden
the first time (in building up the process) that it no longer has to be
synchronised at a higher level.
The reason for this is that the compression techniques all tend to work
much more effectively on systems with many
-actions.
-
Hide all events that are irrelevant to the specification you are trying
to prove.
Hiding can introduce divergence, and therefore invalidate many
failures/divergences model specifications.
However, in the traces model it does not alter the sequence of unhidden
events, and in the stable failures model does not alter refusals which
contain every hidden event.
Therefore if you are only trying to prove a property in one of these
models — or if it has already been established by whatever method that
the system is divergence free — the improved compression we get by
hiding extra events makes it worthwhile doing so.
Two examples of this, one based on the COPY chain example we saw
above and one on the dining philosophers are discussed in more detail in
[RosEtAl95].
The first is probably typical of the gains we can make with compression
and hiding; the second is atypically good.
5.1.3 Hiding and safety properties
If the underlying datatype T of the COPY processes is
large, then chaining N of them together will lead to unmanageably
large state-spaces whatever sort of compression is applied to the entire
system.
Suppose x is one member of the type T; an obviously
desirable (and true) property of the COPY chain is that the
number of x’s input on channel left is always greater than
or equal to the number output on right, but no greater than the
latter plus N.
Since the truth or falsity of this property is unaffected by the
system’s communications in the rest of its alphabet,
{left.y,right.y |
y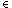
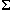 \ {x}},we can hide this set and build the network up a process at a time from
left to right.
At the intermediate stages you have to leave the right-hand
communications unhidden (because these still have to be synchronised
with processes yet to be built in) but nevertheless, in the traces
model, the state space of the intermediate stages grows more slowly with
n than without the hiding.
In fact, with n COPY processes the hidden version
compresses to exactly
2 n [2 to the power n]states whatever the size of T (assuming that this is at least
2).
\ {x}},we can hide this set and build the network up a process at a time from
left to right.
At the intermediate stages you have to leave the right-hand
communications unhidden (because these still have to be synchronised
with processes yet to be built in) but nevertheless, in the traces
model, the state space of the intermediate stages grows more slowly with
n than without the hiding.
In fact, with n COPY processes the hidden version
compresses to exactly
2 n [2 to the power n]states whatever the size of T (assuming that this is at least
2).
If the (albeit slower) exponential growth of states even after hiding
and compressing the actual system is unacceptable, there is one further
option: find a network with either fewer states, or better compression
behaviour, that the actual one refines, but which can still be shown to
satisfy the specification.
In the example above this is easy: simply replace COPY with
Cx=( P
P 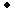 left.x
left.x 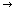 right.x P)
right.x P)
 CHAOS( \
{left.x,right.x})
CHAOS( \
{left.x,right.x})
the process which acts like a reliable one-place buffer for the value
x, but can input and output as it chooses on other members of
T (for the definition of CHAOS, see Processes).
It is easy to show that COPY refines this, and a chain of
n
Cx'scompresses to n+1 states (even without hiding irrelevant external
communications).
The methods discussed in this section can be used to prove properties
about the reliability of communications between a given pair of nodes in
a complex environment, and similar cases where the full complexity of
the operation of a system is irrelevant to why a particular property is
true.
5.1.4 Hiding and deadlock
In the stable failures model, a system P can deadlock if and only
if
P \ can.
In other words, we can hide absolutely all events — and move this
hiding as far into the process as possible using the principles already
discussed.
Consider the case of the N dining philosophers (in a version, for
simplicity, without a Butler process)(12).
A way of building this system up hierarchically is as progressively
longer chains of the form
PHIL0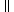 FORK0
PHIL1
... FORKi-1
PHILi
FORK0
PHIL1
... FORKi-1
PHILi
In analysing the whole system for deadlock, we can hide all those events
of a subsystem that do not synchronise with any process outside the
subsystem.
Thus, in this case we can hide all events other than the interactions
between
PHIL0 and FORKN-1, and between
PHILm and FORKm.The failures normal form of the subsystem will have very few states
(exactly 4).
Thus, we can compute the failures normal form of the whole hidden
system, adding a small fixed number of philosopher/fork combinations at
a time, in time proportional to N, even though an explicit
model-checker would find exponentially many states.
We can, in fact, do even better than this.
Imagine doing the following:
-
First, build a single philosopher/fork combination hiding all events not
in its external interface, and compress it.
This will (with standard definitions) have 4 states.
-
Next, put, say, 10 copies of this process together in parallel, after
suitable renaming, to make them into consecutive pairs in a chain of
philosophers and forks (the result will have approximately 4000
states).
Compress this to its 4 states.
-
Now, in the same way, rename this process in 10 different ways so that
it looks like 10 adjacent groups of philosophers, compute the results
and compress it.
-
And repeat this process as often as you like…
Clearly it will take time linear in the number of times you do it.
By this method we can produce a model of
10 N [10 to the power N]philosophers and forks in a row in time proportional to N.
To make them into a ring, all you would have to do would be to add
another row of one or more philosophers and forks in parallel,
synchronising the two at both ends.
Depending on how it was built (such as whether all the philosophers are
allowed to act with a single-handedness) you would either find deadlock
or prove it absent from a system with doubly exponential number of
states.
This example is, of course, extraordinarily well-suited to our methods.
What makes it work are firstly the fact that the networks we build up
have a constant-sized external interface (which could only happen in
networks that were, like this one, chains or nearly so) and have a
behaviour that compresses to a bounded size as the network grows.
On the whole we do not have to prove deadlock freedom of quite such
absurdly large systems.
We expect that our methods will also bring great improvements to the
deadlock checking of more usual size ones that are not necessarily as
perfectly suited to them as the example above.
This document was generated by Phil Armstrong on May 17, 2012 using texi2html 1.82.