SPROUT² is a query answering system that allows users to ask structured queries over tables embedded in Web pages, over Google Fusion tables, over uncertain data extracted by NELL (Never-Ending Language Learning), and over uncertain tables that can be extracted from answers to Google Squared. At the core of this service lies SPROUT, a query engine for probabilistic databases.
A fundamental problem in data management is to uniformly process user queries on collections containing both structured data, such as enterprise data residing in relational databases, and unstructured data, such as Web data. Our approach is to adopt structured views over unstructured data. Such views are intrinsically imperfect or uncertain, since they need to accommodate data that may not agree on the name, type, number of attributes, or even attribute- value pairs, and that may originate from sources of varying degree of trustworthiness. For instance, a business listing appearing on Google Maps often originates from multiple sources, e.g. Yellow Pages, phone companies, business owners themselves, or user generated content; they complement and sometimes contradict each other. Similarly, Google Squared presents answers in tabular form to keyword queries produced by aggregating possibly contradicting data from various Web sources. When compared to offline data, uncertain Web data may have the advantage of exposing different possibilities or opinions about a particular topic and also of being more up-to-date. Moreover, accurate data might not be readily available or known to a majority of users, and uncertain but fast answers might suffice. We demonstrate SPROUT², a query answering system built on top of the query engine SPROUT for uncertain relational data and of existing services that host or aggregate uncertain Web data in tabular form.
Users of SPROUT² can merge uncertain and deterministic data from online Google squares, Google Fusion tables, NELL relations and offline data sources using relational queries with similarity joins and aggregation functions for computing confidences and expected values. SPROUT² has a visual interface that allows (i) browsing Web tables, such as those from Google Fusion Table or Google Squared, and offline tables, and (ii) visually composing queries that join such tables or impose selection criteria on them. SPROUT² can be useful in at least two scenarios: (1) when a user has accurate (deterministic) data available offline or from Web sources such as Google Fusion Table or AggData and would like to enrich it by joining it with recent but uncertain online Web data, and (2) when all data to be joined is gathered from various Web sources in distinct squares. The advantage of using Web squares is that they present a unifying view on recent data from different, possibly contradictory sources.
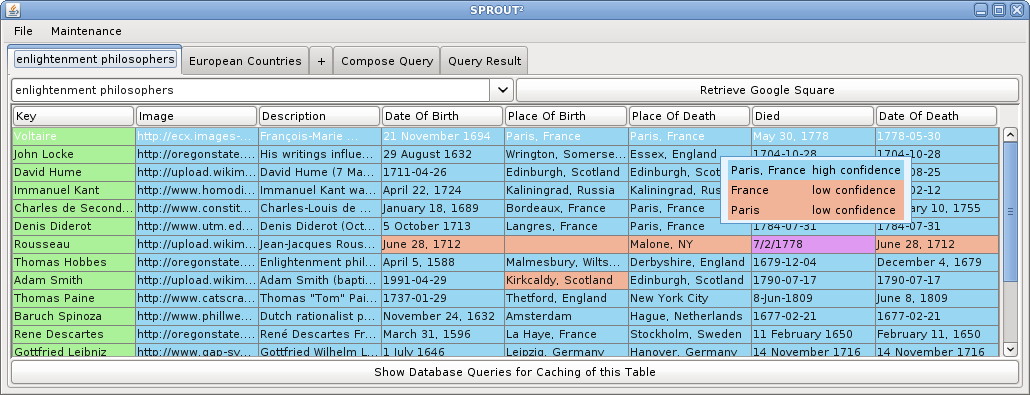
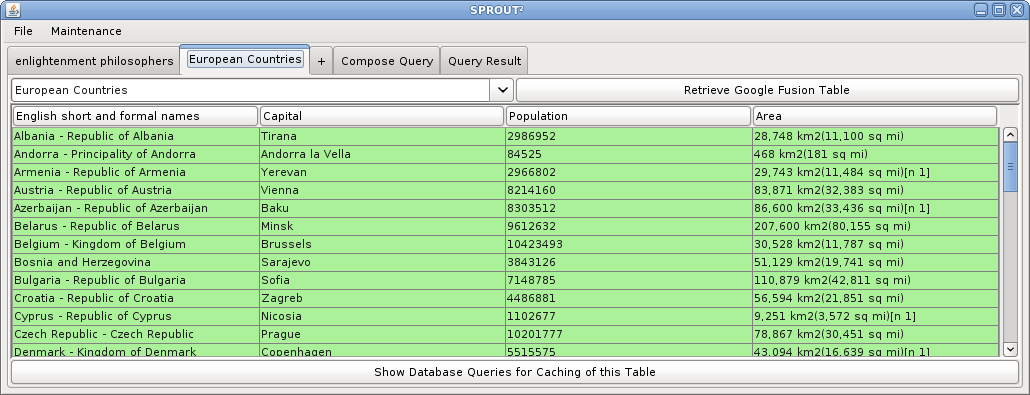
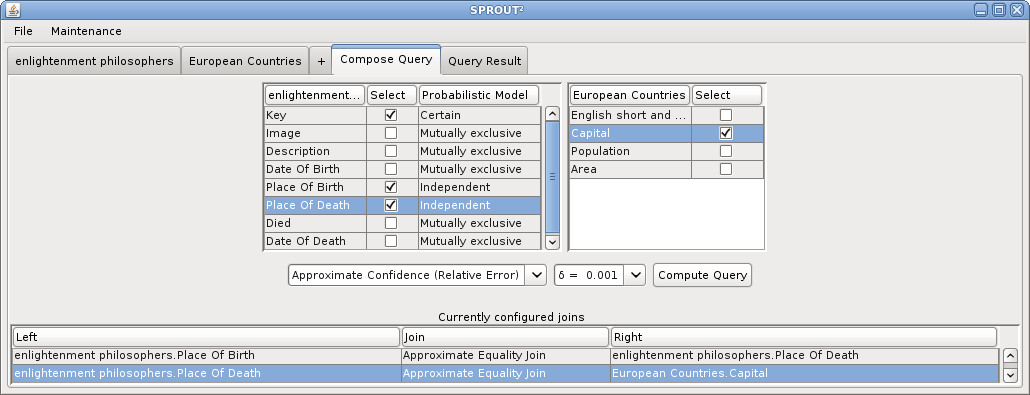
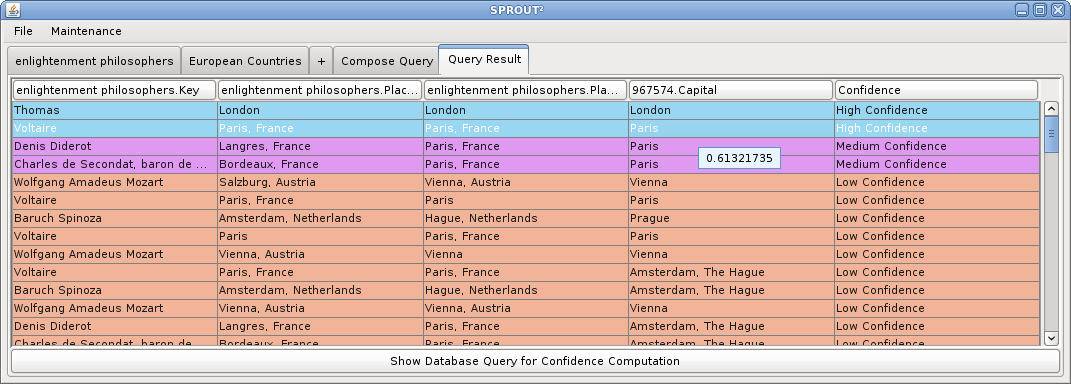
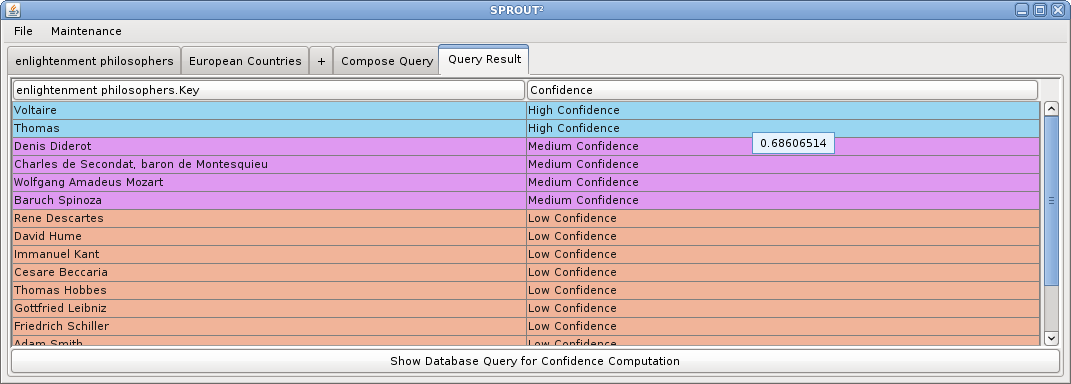
Consider the following example query: 'List enlightenment philosophers that were born and died in a European capital.' The following screen shots illustrate how this query can be answered in SPROUT² using web data sources and a structured query composed in the SPROUT² interface. First, two data sources are defined, (1) a Google square on 'enlightenment philosophers', and (2) a Google Fusion table on European countries and their capitals. Then, joins and projections on those tables are defined. Finally, the query answer is computed and displayed ranked by confidence.
SPROUT² is written in Java and the source code can be provided on request by email. SPROUT² relies on the probabilistic database management system MayBMS and the query engine SPROUT, both of which are available from available on Sourceforge.