
Unravelling the complexities of AI in a team
The key to enabling several artificial intelligence (AI) entities to collaborate is for them to act independently but be trained centrally, according to a University of Oxford team. DPhil students Jakob N Foerster and Gregory Farquhar describe a method developed by computer scientists and engineers which could make it possible to deploy learning multi-agent systems in the real world.
In a fleet of search-and-rescue drones, each single drone typically needs to be able to decide on its best course of action using only local information. This is commonly referred to as 'decentralised execution'. However, often the design of the policies is carried out in a centralised fashion. For example, policies can be trained using a simulator which has access to the observations and actions of all agents.
A fleet of search-and-rescue drones is an example of multi-agent systems that can use learning AI individually while needing to be aware of one another. Our research differs from a lot of AI research, which often focuses on single agent settings and two player games.
We're excited about the possibility of using these methods for the training of autonomous drones or cars...
The world is full of challenging multi-agent problems: these range from self-driving cars to drones and even social interactions. In many of these applications a number of independent entities need to be able to take independent actions based on local observations in order to achieve a common goal. We believe that this domain of centralised training and decentralised execution is one of the key avenues for successfully developing and deploying multi-agent systems in the real world.
One of the great challenges when training multi-agent policies is the credit assignment problem. Just like in a football team, the reward achieved depends on the actions of all of the different agents. Given that all agents are constantly improving their policies, it is difficult for any given agent to evaluate the impact of their individual action on the overall performance of the team.
To address this issue, our team (Computer Science's Jakob Foerster, Gregory Farquhar and Professor Shimon Whiteson, with Engineering's Triantafyllos Afouras and Nantas Nardelli) developed a method called 'Counterfactual Multi-Agent Policy Gradients' (COMA).
We demonstrated the model's potential by using StarCraft, a science fiction strategy game. The problem setting was unit management, which represents a challenging cooperative multi-agent problem.
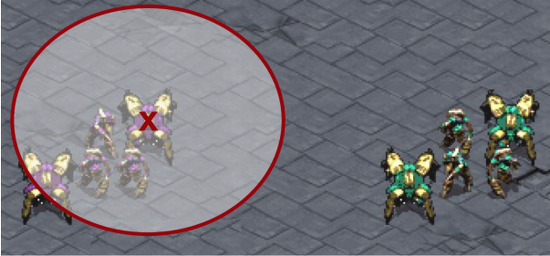
Above: Starcraft, a science fiction strategy game, was used to demonstrate the model's potential
In this setup, each of the units was one agent with partial observability, illustrated by the red circle [see image above]: We extended the actor-critic architecture with a centralised critic which learned expected returns (total points) given the joint action and complete observation of all agents. We then used this centralised critic in order to calculate a 'counterfactual' advantage for each agent.
This advantage compares the expected return after taking a given action to what would have happened had this agent taken a different (counterfactual) action. While evaluating each counterfactual in turn might seem slow and computationally expensive, we used deep learning to efficiently compute the counterfactual values in parallel.
Importantly, once the training was finished we threw away the critic and deployed the policies, allowing for decentralised execution. Putting everything together we obtained a training method which outperformed existing methods and achieved high win rates against the StarCraft bot.
This COMA method was described in a paper which won the 'Outstanding Student Paper Award' at the Association for the Advancement of Artificial Intelligence's conference, AAAI 2018, in February. The project was funded by the ERC and under the EU's Horizon 2020 Research and Innovation programme.
Our team is continuing to research further challenges in multi-agent coordination and exploration. We're excited about the possibility of using these methods for the training of autonomous drones or cars, which must learn to coordinate in the real world without being able to reliably communicate.
The full paper is at: goo.gl/CZ9n92
This article first appeared in the summer 2018 issue of Inspired Research.