
Are we safe in self-driving cars?
The safety of self-driving cars relies on the accuracy of the deep neural networks that control them. To verify the performance of these networks, the department is developing model checking techniques, as Professor Marta Kwiatkowska explains.
Deep neural networks (DNNs) have achieved impressive results, matching the cognitive ability of humans in complex tasks such as image classification, speech recognition or Go playing. Many new applications are envisaged, including cancer diagnosis and self-driving cars, where DNN solutions have been proposed for end-to-end steering, road segmentation and traffic sign classification.
However, the reasons behind DNNs' superior performance are not yet understood. They are also unstable with respect to so called adversarial perturbations that can fool the network into misclassifying the input, even when the perturbation is minor or imperceptible to a human.
To illustrate the problem consider the figure below, which shows an image of a traffic light taken in Oxford (on the left) that is correctly recognised as a red light by the YOLO Real-Time Object Detection network, but after the image is perturbed by adding 11 white pixels the image is classified as an oven. To make matters worse, when these images are printed and photographed at several different angles and scales and then fed to the network, they remain misclassifie.

Moreover, adversarial examples are transferable, in the sense that an example misclassified by one network is also misclassified by a network with another architecture, even if it is trained on different data.
Adversarial examples raise potential safety concerns for self-driving cars: in the context of steering and road segmentation, an adversarial example may cause a car to steer off the road or drive into barriers, and misclassifying traffic signs may lead to a vehicle driving into oncoming traffic.

As an illustration, let us consider the Nexar traffic light challenge (details at: goo.gl/MnF3vx), which made over 18,000 dashboard camera images publicly available, as part of a challenge to researchers to teach deep networks to identify traffic lights. Each image, such as that above, is labelled either green, if the traffic light appearing in the image is green, or red, if the traffic light appearing in the image is red, or null if there is no traffic light appearing in the image.
In the figure below, one can demonstrate that, for the deep network that won the challenge, a change of just one pixel is enough to force it into classifying the image that any human would perceive as a red light into a green light, and do so with high confidence.
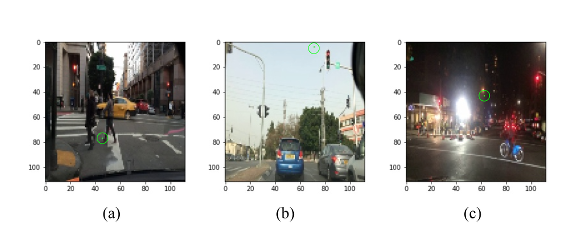 [Above] SafeCV applied to Nexar Traffic Light Challenge. (a) Red light classified as green with 68% confidence after one pixel is changed.
(b) Red light classified as green with 95% confidence after one pixel is changed. (c) Red light classified as green with 78% confidence after one pixel is changed.
[Above] SafeCV applied to Nexar Traffic Light Challenge. (a) Red light classified as green with 68% confidence after one pixel is changed.
(b) Red light classified as green with 95% confidence after one pixel is changed. (c) Red light classified as green with 78% confidence after one pixel is changed.
Safety of AI systems is the most pertinent challenge facing us today, in view of their autonomy and the potential to cause harm in safety-critical situations. Safety assurance methodologies are therefore called for. One of the most successful techniques to ensure system safety and reliability is model checking, now used in industry, for example at Intel, Microsoft and Facebook. Model checking employs techniques derived from logic and automata to verify - automatically, that is, with the help of a computer program - that the software or hardware system meets the desired specifications.
Model checking techniques for machine learning, and neural networks in particular, are little studied and hampered not only by poor understanding of their theoretical foundations, but also their huge scale, with DNNs routinely containing millions of parameters. In this direction, with support from the five-year EPSRC Programme Grant on Mobile Autonomy, which began in 2015, I am developing techniques for safety verification of deep neural networks.
In contrast to existing work, which employs optimisation or stochastic search, the idea here is to automatically prove that no adversarial examples exist in a neighbourhood of an image and therefore the network can be deemed safe for a decision based on this image. I presented the results for several stateof-the-art networks and future challenges for this work in a keynote presentation at the 2017 Computer Aided Verification (CAV) conference in Heidelberg. The presentation can be watched at: goo.gl/5zinuD
In a further paper just released on this topic (which can be found at goo.gl/yEKLDD), a software package called SafeCV has been developed to test the robustness of a DNN image classifier to adversarial examples. The main contribution is a method to search for adversarial examples guided by features extracted from the image, which uses computer vision techniques and relies on a Monte Carlo tree search algorithm. The software has been evaluated on state-of-the-art neural networks, demonstrating its efficiency in evaluating the robustness of image classifier networks used in safetycritical applications, which is sufficiently fast to enable real-time decision support.
The adversarial images included in this article were, in fact, found automatically by SafeCV. Images of Oxford traffic lights were taken by Matthew Wicker, studying at the University of Georgia and co-author of the paper, who visited Oxford for a summer internship.
Despite some progress, many challenges have to be overcome before we are able to prove that self-driving cars are safe. Chief among them is scalability of the verification techniques to large-scale images, where symbolic methods employed in conventional model checking may offer a solution. Another challenge is how to correct a flawed network, which can be addressed through retraining, fixing errors or even redesigning. Finally, for neural networks that learn as the system executes, for example reinforcement learning, we will need to move beyond design-time safety assurance towards monitoring and enforcement of decision safety at run time.
This article first appeared in the Winter 2017 issue of Inspired Research.