Contents
Software Verification for Weak Memory via Program Transformation
Abstract
Multiprocessors implement weak memory models, but program verifiers often assume Sequential Consistency (SC), and thus may miss bugs due to weak memory. We propose a sound transformation of the program to verify, enabling SC tools to perform verification w.r.t. weak memory. We present experiments for a broad variety of models (from x86-TSO to Power) and a vast range of verification tools, quantify the additional cost of the transformation and highlight the cases when we can drastically reduce it. Our benchmarks include work-queue management code from PostgreSQL.News
- 1st of December 2012: Corrected machine definition on Coq proofs.
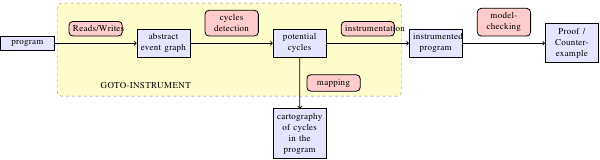
- 5th of October 2012: New sound, optimised strategy for instrumenting critical cycles implemented in Goto-instrument
- 4th of July 2012: We now analyse Apache's fdqueue module
- 24th of June 2012: Concurrent CBMC added to the set of model-checkers used for the experiments
- 22nd of February 2012: We will report distinct results for Poirot with integer vs. bitvector arithmetic
- 8th of February 2012: SatAbs is now able to handle RCU!
- 23rd of January 2012: Release of the tool
Proofs
Proofs of the paper, formalised in Coq.Tool manual
Here is the manual of the tool, and how to plug in a model-checker (we have tried CheckFence, ESBMC, MMChecker, Poirot, SatAbs, Threader and our new CBMC-MT).
Case Study: Fixing a WMM bug in PostgreSQL
We show here how we can detect this bug for Power reported by PostgreSQL developers.
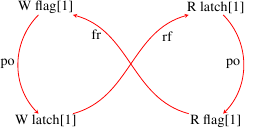
We then test their fix (the reader should search for the comment "XXX there really ought to be a memory barrier operation right here" in the diff). We show that this fix might not be sufficient, we provide a counter-example generated by our tool, and we propose an additional fix, which provably fixes the problem.
Summary of systematic testing for CBMC
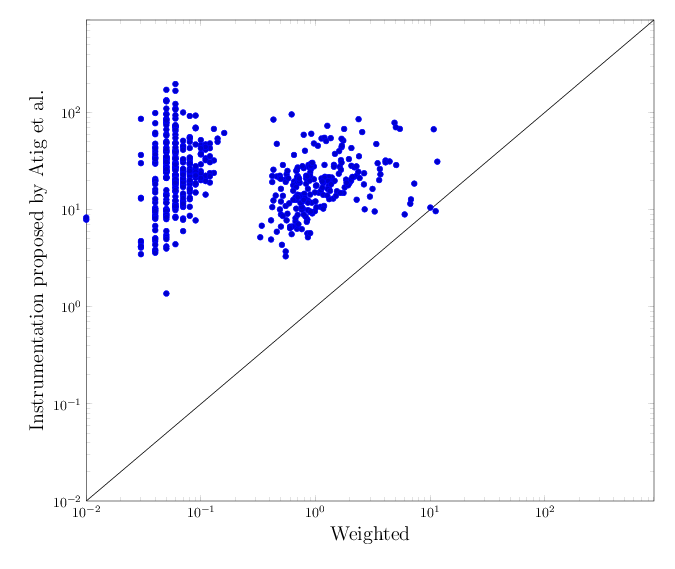
Here are the average runtime and overhead for CBMC, on all litmus tests. We provide the same data for all model-checkers, on all litmus tests but also on C examples below.The following scatter plot (click for more details and an enlarged version) depicts the execution time of running CBMC on a program whose all accesses are instrumented, as proposed by Atig et al., vs. execution times for the optimised instrumentation using weighted selection under TSO. Any dot below the diagonal line marks a case where full instrumentation is slower than the optimised one.
Experiments
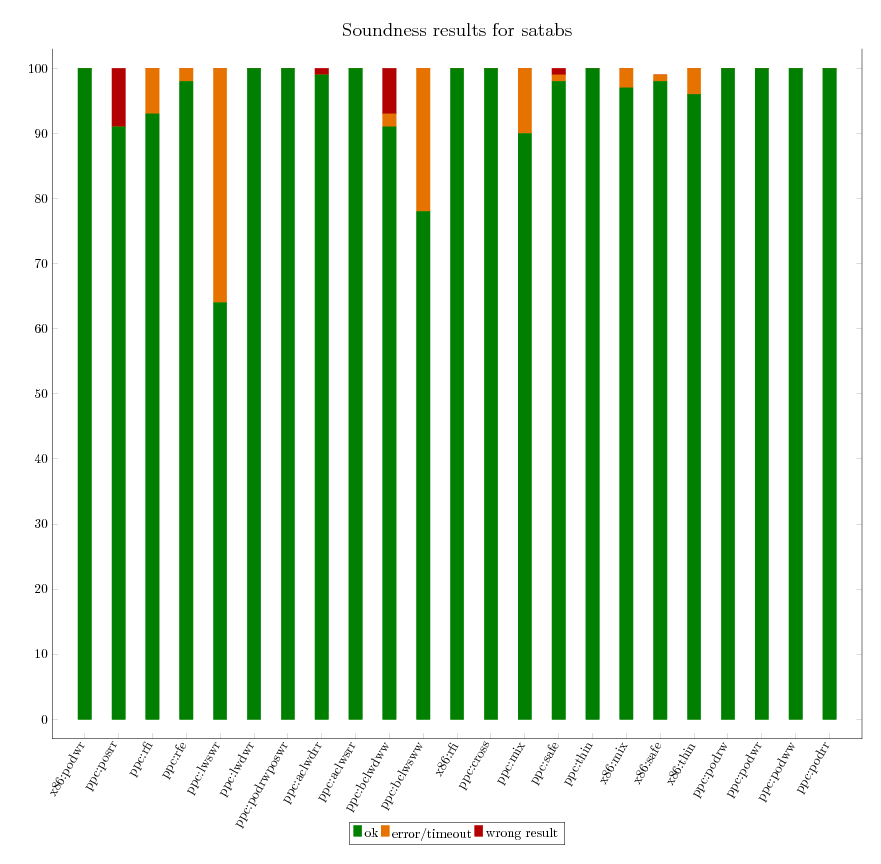
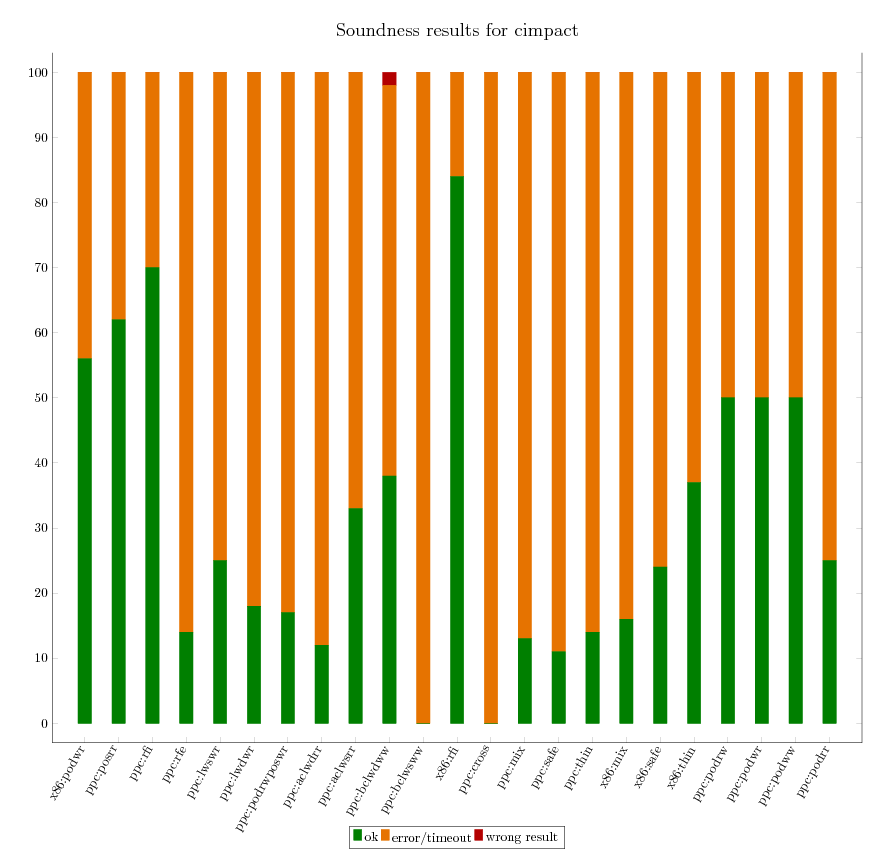
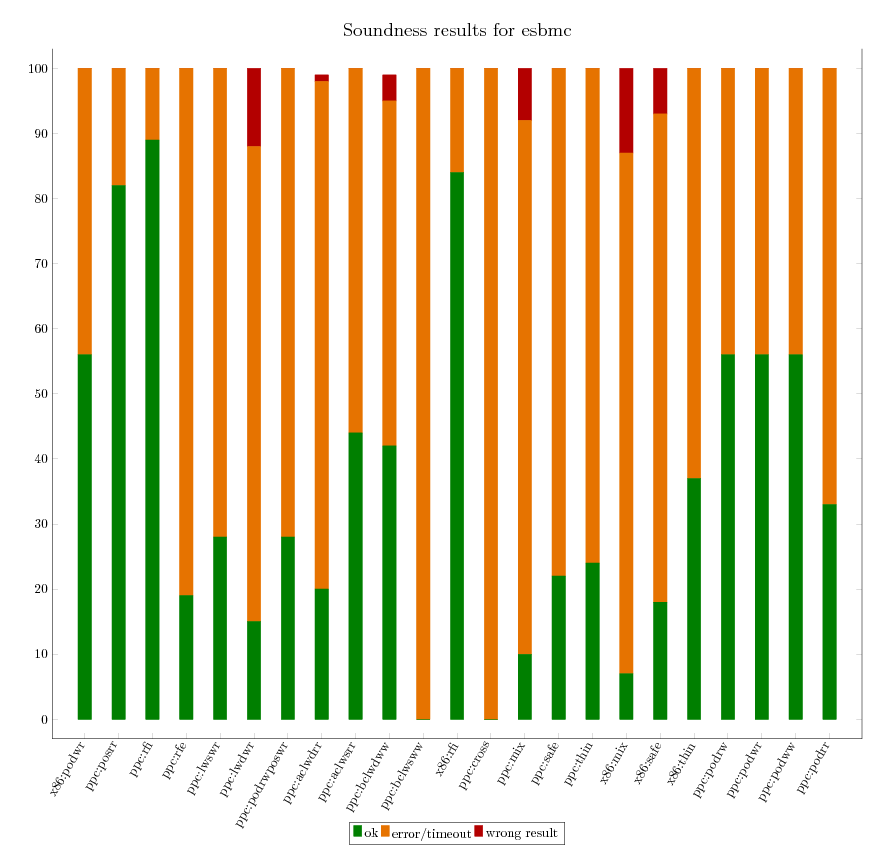
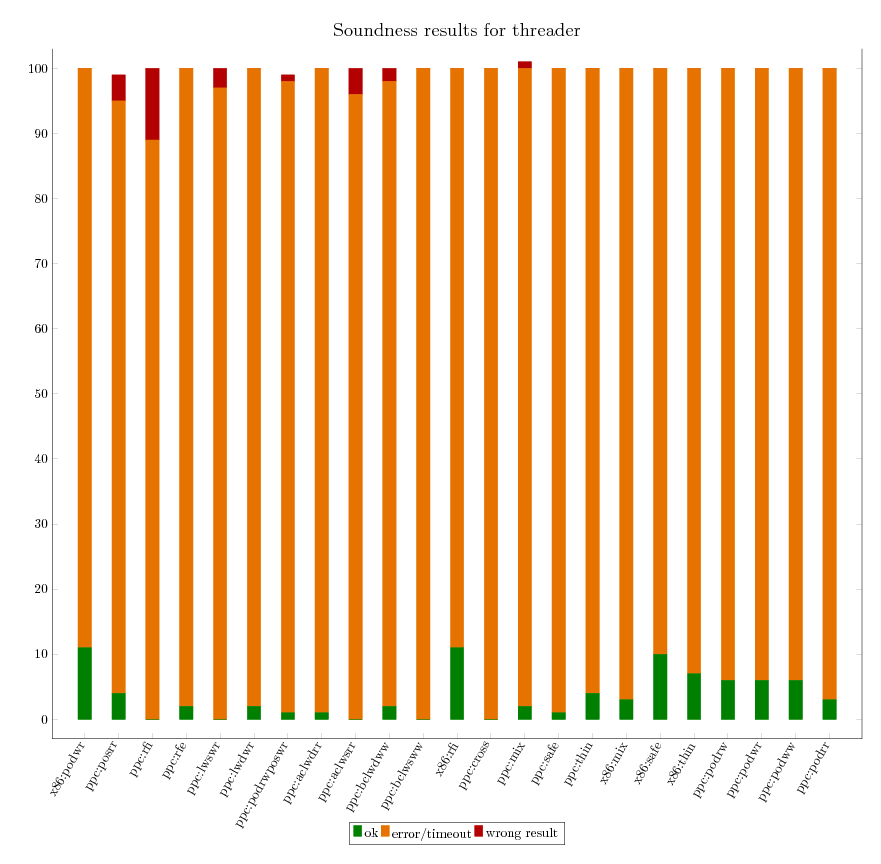
Here are all our experimental data, for all model-checkers, on all litmus tests and C examples, including standard ones, borrowed ones, the PostgreSQL bug, and RCU.
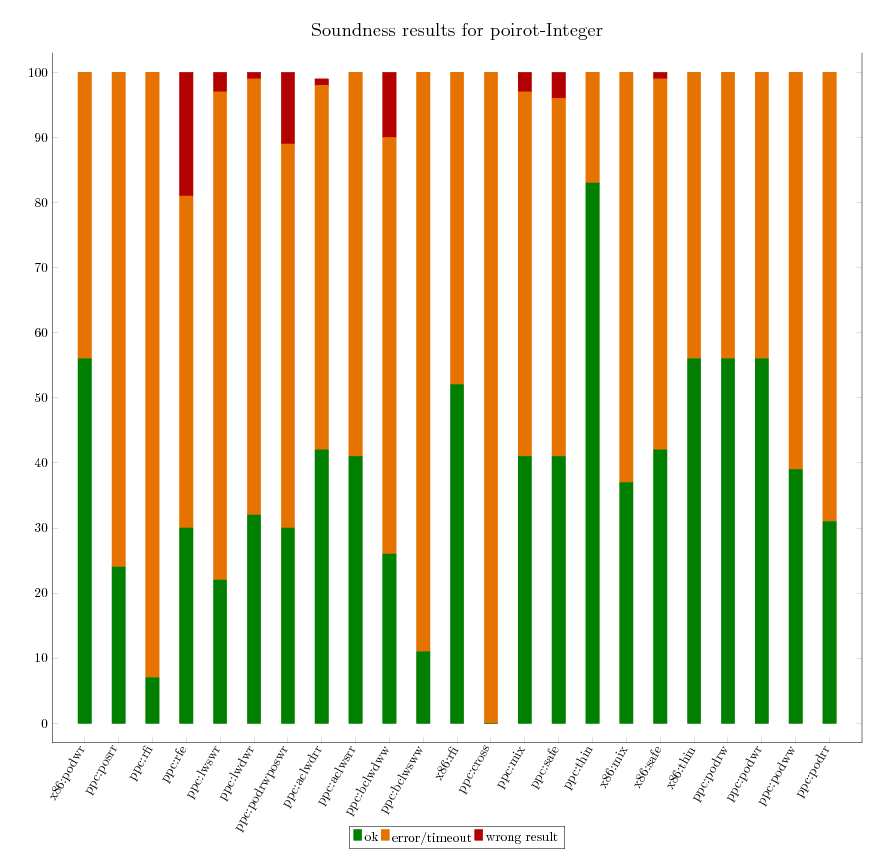
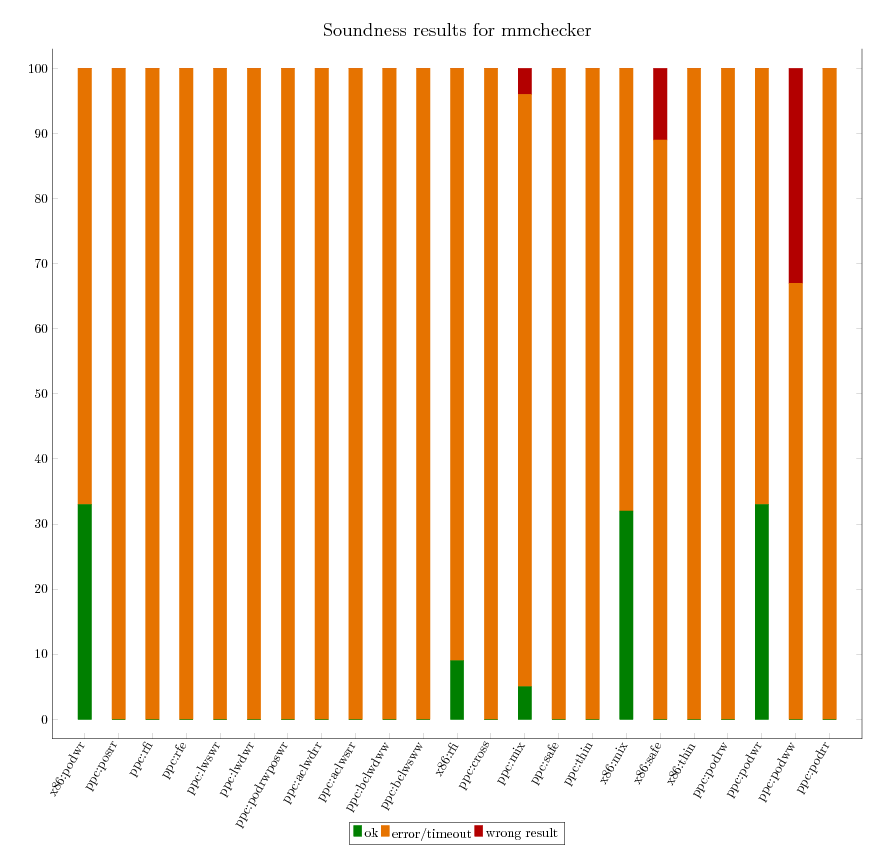
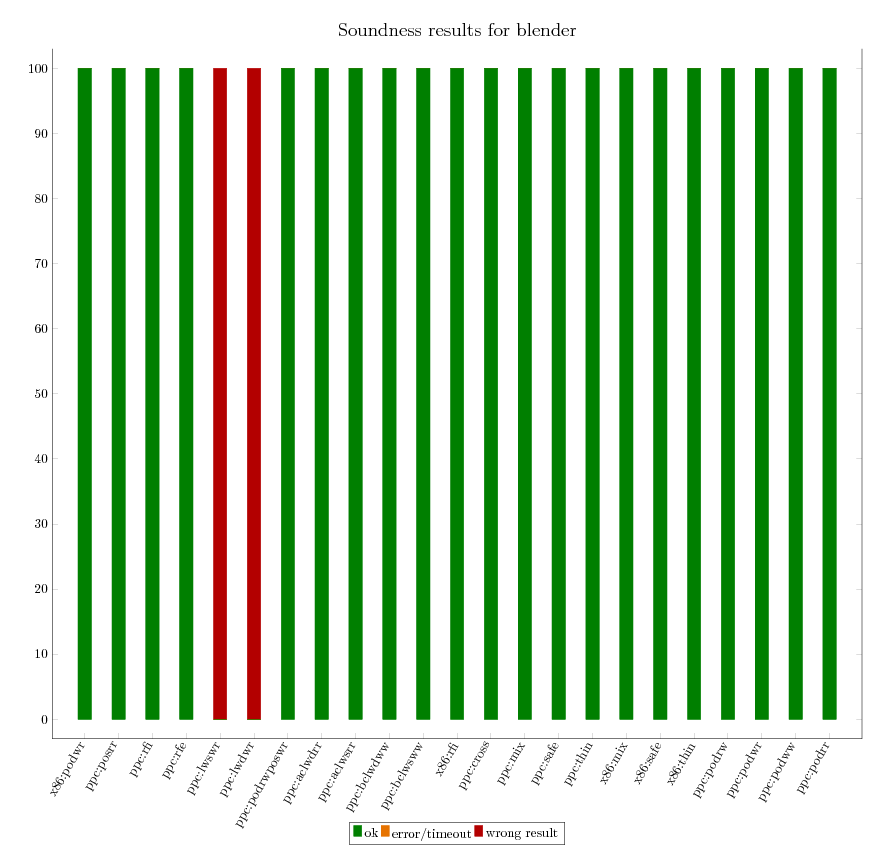
As we can independently compute the expected verification result for all litmus
tests, we are able to assess the soundness of each of the verification
tool. The following graphics provide an executive summary of this assessment.