The Science of Deep Learning
December 17th, 2015
The field in which we work, applied machine learning (and deep learning in particular), is a unique one. It mixes together engineering, mathematics, natural sciences, and even social sciences. We develop tools trying to explain the world, extrapolate it, and interpolate it. The natural and social sciences often make use of these tools to try and explain observed phenomena. But for many of the tools we develop (especially in deep learning) we have a very limited understanding of why they themselves work... That's been bothering me for quite some time now, and I used my time at the last NIPS conference discussing this with anyone willing to listen to me. One possible solution that comes to mind is quite beautiful (in a circular sort of way). We can adopt methodology from the natural sciences back into machine learning to try to understand itself. Such a scientific view of the field has the potential to transform it completely.
Note: there is an interactive element to this post (see below). If you're here following the link in the paper ''A Theoretically Grounded Application of Dropout in Recurrent Neural Networks'', please see the discussion board at the bottom.

Making fire through empirical experimentation. (Photos taken from Wikimedia under Creative Commons license)

Making fire following theoretical developments.
Scientific Methodology in Deep Learning
How do we go about applying the scientific methodology in a field such as deep learning? We start by identifying empirically developed tools that work well, but which we do not necessarily understand. We will go over some concrete examples below. We develop hypotheses, attempting to explain the underlying principles of these tools that work well. We then propose testable predictions, trying to validate or falsify different ideas. These require experimentation again, and often result in new tools that improve on existing ones. Adapting the suggested hypotheses to the new results we continue this cycle, developing a better and better understanding of the world.
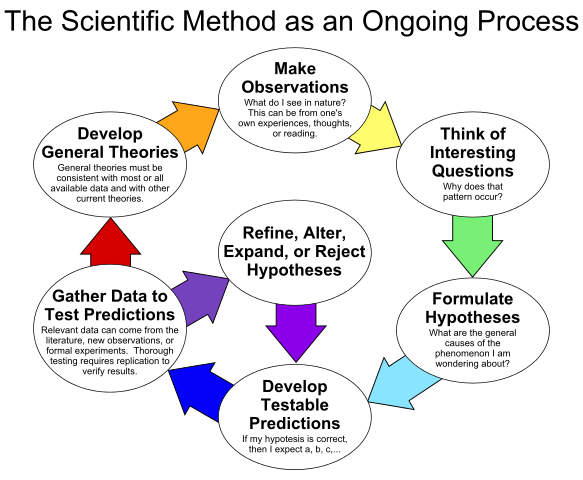
An example of the methodology as is applied in the natural sciences. In our case we would look for unexplained tools that work well as our natural phenomena.
What's unique to our field, however, is that a single person can go through the entire cycle alone (and in one day!). In most sciences, going through the experimentation phase often requires specialised expertise and apparatus. Physics for example is split into theoretical and experimental branches, each one requiring years of training. In our case, however, we work with data — and both the theory and the experiments are ''virtual''. A single person can come up with a theoretical justification for an observed phenomenon, develop predictions and code-up an experiment to test these. This is both a blessing on the field, and a curse. On the one hand it is important to have a good understanding of both aspects of the work to come up with good theories and experiments. But on the other hand, implementing experiments often requires excellent engineering expertise, and developing good theories requires a broad understanding of the mathematical tools we have at hand. Becoming an expert in both these areas is not an easy job.
A concrete example
If you read my last blog post the ideas above might sound familiar. In the last post we looked at dropout (Srivastava et al.), a technique often used for model regularisation in deep learning. Our observed phenomenon was that dropout works really well in avoiding overfitting and improving model performance. We offered a theoretical explanation for why the technique works well (relying on Bayesian probability theory), which we used to obtain uncertainty estimates in deep learning. By doing this, in essence, we made a prediction following the theory: we expected the output of a certain procedure to correspond to model uncertainty. We then tested the prediction with several experiments (as was done here). More recent results with convolutional neural networks (CNNs) allowed us to test the theory further. The theory suggested, for example, new ''Bayesian CNN'' model structures that improved on state-of-the-art in image classification (see here). This is a nice example of when a theoretical understanding of our tools can lead to new and better tools. Many other such examples have been suggested recently (such as Hardt et al., Dauphin et al., Choromanska et al.).

Science!
Falsification
We have many examples of hypotheses trying to explain different phenomena in applied machine learning. However, an integral part of the scientific method – and a key component in the cycle above – has so far been overlooked: Falsification. Basically, trying to find predictions from a theory which do not hold, forcing us to rethink and improve the theory. Falsification is not necessarily the same as finding negative results. Negative results can be found through a process of trial and error as well, detached from any hypothesis. For example, it was recently observed that batch normalisation fails in certain network structures. But we have no hypothesis to alter or reject following this observation. In the process of falsification we start by identifying a prediction made by a theory, and then try to refute the prediction by planning an experiment that will show the contrary.
Interactive experimentation
Let's play with an example where empirical approaches with dropout fail. Recurrent neural networks (RNNs) are models that can capture sequences. These powerful models form a key part in many language processing tasks (as you can see in this brilliant blog post by Karpathy for example) but also overfit very quickly. Yet we don't know how to apply dropout in RNNs. Many empirical approaches have seen limited success (I counted at least 5! [1, 2, 3, 4, 5]).
Following the theory above, though, the correct approach seems relatively straight-forward: use the same mask at all time steps. Preliminary tests seem to support this as well. I've decided to experiment with this latest papers: I've put the preliminary draft for the paper ''A Theoretically Grounded Application of Dropout in Recurrent Neural Networks'' online here. The paper lays out theoretical foundations for a mathematically grounded application of dropout in RNNs, but with a limited experimental evaluation.
And this is where the interactive part begins. Your task is to brainstorm what experiments you think might falsify or support the claims above. In the discussion below you can express your opinion on the paper / bring up things you'd like to see in future versions / complain about the lack of experiments / and so on. Basically, I'm giving you the chance to ''break my work''.
Hopefully, this interactive form of research will lead to some interesting and exciting new results.
Discussion
Acknowledgements
I'd like to thank Chris Bishop and Mark van der Wilk for some thought-provoking discussions. Further thanks go to Adrian Weller and Ed Grefenstette for helpful feedback on early versions of the post.

